
Alocare latentă Dirichlet
În prelucrarea limbajului natural, alocarea latentă Dirichlet, prescurtat LDA (engleză latent Dirichlet allocation), este un model statistic generativ care permite explicarea unor mulțimi de observații prin grupuri neobservate care explică de ce unele submulțimi din date sunt similare. De exemplu, dacă observațiile sunt cuvinte adunate din documente, se postulează că fiecare document este un amestec de un număr mic de teme și că prezența fiecărui cuvânt în acel document se datorează uneia dintre temele abordate în document. LDA este un exemplu de modelare a temelor.
Istoric[modificare | modificare sursă]
În contextul geneticii populației, LDA a fost propus de J. K. Pritchard, M. Stephens și P. Donnelly în anul 2000[1]. În contextul învățării automate, domeniul în care este cel mai aplicat astăzi, LDA a fost redescoperit în mod independent de către David Blei, Andrew Ng și Michael I. Jordan în 2003 și a fost prezentat ca un model grafic pentru descoperirea temelor[2]. Începând cu 2019, aceste două lucrări au 24.620 și respectiv 26.320 citări, ceea ce le face printre cele mai citate din domeniile învățării automate și inteligenței artificiale[3][4].
Teme[modificare | modificare sursă]
În LDA, fiecare document poate fi privit ca un amestec de diferite teme, unde fiecare document este considerat a avea o mulțime de teme care îi sunt atribuite prin LDA. Această metodă este identică cu analiza semantică latentă probabilistică (pLSA), cu excepția faptului că în LDA se presupune că distribuția temelor are o distribuție Dirichlet a priori rară. Distribuția Dirichlet rară codifică intuiția că documentele acoperă doar o mulțime mică de teme și că temele folosesc doar o mulțime mică de cuvinte în mod frecvent. În practică, acest lucru duce la o mai bună dezambiguizare a cuvintelor și la o mai precisă atribuire a documentelor la teme. LDA este o generalizare a modelului pLSA, care este echivalent cu LDA cu o distribuție Dirichlet a priori uniformă[5].
De exemplu, un model LDA ar putea avea teme care pot fi clasificate ca PISICĂ și CÂINE. O temă are probabilități de a genera diverse cuvinte, precum lapte, miau și pisoi, care pot fi clasificate și interpretate de către cititor ca „PISICĂ”. Desigur, cuvântul pisică va avea probabilitate mare dată această temă. Tema CÂINE are, de asemenea, probabilități de a genera fiecare cuvânt, unde cățeluș, lătrat și os ar putea avea probabilitate mare. Cuvintele fără relevanță specială, precum „și” (vezi cuvinte gramaticale), vor avea aproximativ aceeași probabilitate între clase (sau pot fi plasate într-o categorie separată). O temă nu este puternic definită nici semantic, nici epistemologic. Este identificată pe baza detectării automată a probabilității co-apariției termenilor. Un cuvânt lexical poate să apară în mai multe teme cu probabilitate diferită, dar de obicei cu un alt set de cuvinte învecinate în fiecare temă.
Se presupune că fiecare document poate fi caracterizat de un anumit set de teme. Acest lucru este similar cu modelul sacului de cuvinte standard, unde cuvintele individuale sunt inter-schimbabile.
Model[modificare | modificare sursă]

Folosind notația cu plăci, care este adesea folosită pentru a reprezenta modele grafice probabilistice (MGP), dependențele dintre mai multe variabile pot fi capturate concis. Dreptunghiurile sunt „plăci” și reprezintă replici, care sunt entități repetate. Placa exterioară reprezintă documente, în timp ce placă interioară reprezintă pozițiile cuvintelor într-un anumit document în mod repetat, iar fiecare dintre poziții este asociată cu o temă și un cuvânt. M reprezintă numărul de documente, iar N este numărul de cuvinte într-un document. Variabilele sunt definite după cum urmează:
- α este parametrul distribuției Dirichlet a priori a distribuției temelor per document,
- β este parametrul distribuției Dirichlet a priori a distribuției cuvintelor per temă,
- este distribuția temelor pentru documentul i,
- este distribuția cuvintelor pentru tema k,
- este tema pentru al j-lea cuvânt din documentul i, și
- este cuvântul propriu-zis.
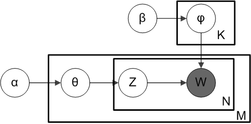
Notația cu plăci pentru LDA cu distribuțiile temă-cuvânt distribuite Dirichlet





Este utilă imaginarea entităților reprezentate de și ca matrici create prin descompunerea matricii originale document-cuvânt care reprezintă corpusul de documente care a fost modelat. Așadar, este formată din rânduri definite de documente și coloane definite de teme, în timp ce este format din rânduri definite de teme și coloane definite de cuvinte. Astfel, se referă la un set de rânduri, sau vectori, fiecare fiind o distribuție peste cuvinte, iar se referă la un set de rânduri, fiecare fiind o distribuție peste teme.




Note[modificare | modificare sursă]
- ^ Pritchard, J. K.; Stephens, M.; Donnelly, P. (iunie 2000). „Inference of population structure using multilocus genotype data”. Genetics. 155 (2): pp. 945–959. ISSN 0016-6731.
- ^ Blei, David M.; Ng, Andrew Y.; Jordan, Michael I (ianuarie 2003). Lafferty, John, ed. „Latent Dirichlet Allocation”. Journal of Machine Learning Research. 3 (4–5): pp. 993–1022. doi:10.1162/jmlr.2003.3.4-5.993.
- ^ „- Google Scholar”. scholar.google.ca. Accesat în .
- ^ „- Google Scholar”. scholar.google.ca. Accesat în .
- ^ Girolami, Mark; Kaban, A. (). On an Equivalence between PLSI and LDA (PDF). Proceedings of SIGIR 2003. New York: Association for Computing Machinery. ISBN 1-58113-646-3.